Hi, all
I want to change the point cloud data stored in ASCII format using C ++ to the pnts binary format used by Cesium (http://cesiumjs.org).
I’m having difficulty in creating a binary format file using specification information because I do not have enough understanding about data types and binary files.
The specification of the pnts format and the attribute information of the header are shown in Figure 1 and 2.
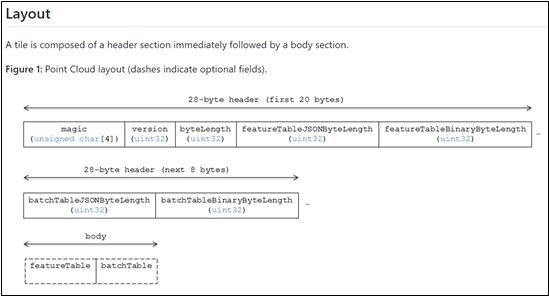
Figure 1
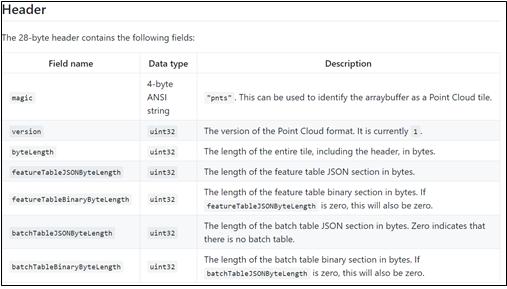
Figure 2
Currently, I’m analyzing the header portion of the binary-formatted sample file (test.points) and the results are shown in Figure 3.
The contents of the pnts file were changed to hexadecimal notation using Notepad ++, and these values were converted to decimal digits and confirmed.

Figure 3
magic, version, and byteLength are interpreted correctly, but the remaining FeatureTableJSONByteLength, FeatureTableBinaryByteLength, batchTableJSONByteLength, and batchTableBinaryByteLength are much larger than I expected.
In the description of the header field above, I thought that the size of the byte buffer of FeatureTableJSONByteLength would not exceed the total byte length, but it was too large.
Please comment whether I misinterpreted it or if it was generated differently when creating the sample file, or if the approach was wrong when creating the file using the format specification.
Thank U
Which test.pnts file are you referring to?
https://drive.google.com/file/d/0B4fUL_mhs4L3b2ZjTHZOTEM0NVU/view ← This is a pnts format.
{
“asset”: {
“version”: “0.0”
},
“geometricError”: 10000,
“refine”: “add”,
“root”: {
“boundingVolume”: {
“sphere”: [-2505606.7412357354,
-3847564.4813386216,
4412182.937547942,
100]
},
“geometricError”: 0,
“content”: {
“url”: “s-0001.pnts”
},
“children”:
}
} json format.
I’m not sure what to suggest. It seems like a bug in the tool that created the .pnts file.
I’m sorry to see you reply late.
But what is the exact meaning of the bug?
I could help find the bug, but I would need to see the code that generates the pnts files.
Thank you for answer.
pnts sample data in this post is from following site.
Source: http://points.chicago.vision/
If there is a bug in this pnts file, could you provide me a sample pnts data and json file to analyze format specification?
Then, I will decode the sample pnts data using pnts format spec information. (It will help me to make pnts format convertor)
If possible, I would like to see a detailed description of the attribute information type in the pnts file or the codes that generate the pnts file.
such as magic = “pnts”
version = 1
ByteLength = 3440 Byte
featureTableJSONByteLength = ??? <- I don’t know exact meaning
featureTableBinaryByteLength = ???
batchTableJSONByteLength = ???
batchTableBinaryByteLength = ???
We would also appreciate if you can include the text information in the JSON Header Body part.
I will wait for your reply again.
Thank you for answer.
The information you give me is still being watched.
While waiting for an answer, I made a pnts file myself and need to make sure it was created properly.
If there is a problem with the file, please let me know where the problem is.
(I uploaded the pnts file.)
I will wait for your reply again.

figure1. Pnts file seen in hex

figure2. property value in C ++

figure3. This is my c ++ code
Sample.pnts (122 Bytes)
The feature table JSON needs to be a JSON string like “{POINTS_LENGTH : 4, POSITION : {byteOffset: 0}}”. Otherwise it seems okay at a glance.
Make sure to also consider padding: https://github.com/AnalyticalGraphicsInc/3d-tiles/tree/master/TileFormats/FeatureTable#implementation-notes
Thanks again for answer.
“The string generated from the JSON header should be padded with space characters in order to ensure that the binary body is byte-aligned“
I saw this sentence in Implementation Notes.
But, I do not know exactly what it means to consider padding (padded with space characters)
Can you give examples or explain in detail?
The binary sections of a tile must be byte-aligned, meaning their byte offset within the entire binary should be a multiple of their type. For example, if storing point positions represented as 32-bit floats, that section’s byte offset must be divisible by 4.
An example implementation is here: https://github.com/AnalyticalGraphicsInc/3d-tiles-tools/blob/master/generator/lib/createPnts.js
Thank you for your reply every time.
Currently,I am testing with the viewer included in this link.
( http://points.chicago.vision/ )


However, the pnts file created by me is not properly displayed in the viewer.
Perhaps there seems to be a problem with pnts.
I’m sorry, but I want you to check for any problems with pnts.
Thank you.
s-0001.pnts (117 KB)
The feature table JSON is not valid JSON. “{POINTS_LENGTH:100,POSITION:{byteOffset:0}}” should instead be "{“POINTS_LENGTH”:100,“POSITION”:{“byteOffset”:0}}.
Thank you for quick response.

I changed the code as you said, but the same problem occurred.
After checking it, I found that there was a problem with the pnts file itself.
It’s probably a problem with the code, but I want to know if the spec I wrote will work just fine. Or should I fill in anything else?
And last time you said there was a bug in the Chicago vision pnts file,
I want to know why the output is normal.
( I will upload the file. )
https://drive.google.com/file/d/0B3Bx1ivXoFaZUE9HUE9GbmUzRXc/view?usp=sharing
https://drive.google.com/file/d/0B3Bx1ivXoFaZWXBvMnR6eFQ3SGM/view?usp=sharing
https://drive.google.com/file/d/0B3Bx1ivXoFaZaVhnem15ZE9FVkU/view?usp=sharing
https://drive.google.com/file/d/0B3Bx1ivXoFaZeDdMYU1hMldtcTA/view?usp=sharing
I’m sorry to have many questions.
Thank you very much.

( This is the point cloud I want )
With the new JSON string the byte alignment for the feature table binary is now off, that’s the main problem I see at the moment.
This is actually good timing because we started working on a validator that should help catch problems like these. Check out our work-in-progress branch here: https://github.com/AnalyticalGraphicsInc/3d-tiles-tools/tree/validator/validator. You can run validation for either the json or the pnts file.
Thanks to your many answer, I have completed the pnts file using C++
Thank you very much.
Finally, I want to ask one more thing


As shown above
I want to match the point cloud with the ground, but it does not work well
I’d like you to advise me if I should use the transformation matrix or change the coordinates.
That looks very nice!
The easiest way to match the ground would be to change the coordinates. The transformation is sometimes tricky to get right. Usually the transformation works best if the positions are centered at the origin and axis-aligned to begin with. It’s hard to say which approach is best because it often depends on the source data.
